链接器
为了更好地理解计算机程序的编译和链接的过程,我们简单地回顾计算机程序开发的历史一定会非常有益。计算机的程序开发并非从一开始就有着这么复杂的自动化编译、链接过程。原始的链接概念远在高级程序语言发明之前就已经存在了,在最开始的时候,程序员(当时程序员的概念应该跟现在相差很大了)先把一个程序在纸上写好,当然当时没有很高级的语言,用的都是机器语言,甚至连汇编语言都没有。当程序须要被运行时,程序员人工将他写的程序写入到存储设备上,最原始的存储设备之一就是纸带,即在纸带上打相应的孔。
这个过程我们可以通过下图来看到,假设有一种计算机,它的每条指令是1个字节,也就是8位。我们假设有一种跳转指令,它的高4位是0001,表示这是一条跳转指令;低4位存放的是跳转目的地的绝对地址。我们可以从图中看到,这个程序的第一条指令就是一条跳转指令,它的目的地址是第5条指令(注意,第5条指令的绝对地址是4)。至于0和1怎么映射到纸带上,这个应该很容易理解,比如我们可以规定纸带上每行有8个孔位,每个孔位代表一位,穿孔表示0,未穿孔表示1。

现在问题来了,程序并不是一写好就永远不变化的,它可能会经常被修改。比如我们在第1条指令之后、第5条指令之前插入了一条或多条指令,那么第5条指令及后面的指令的位置将会相应地往后移动,原先第一条指令的低4位的数字将需要相应地调整。在这个过程中,程序员需要人工重新计算每个子程序或跳转的目标地址。当程序修改的时候,这些位置都要重新计算,十分繁琐又耗时,并且很容易出错。这种重新计算各个目标的地址过程被叫做重定位(Relocation)。
如果我们有多条纸带的程序,这些程序之间可能会有类似的跨纸带之间的跳转,这种程序经常修改导致跳转目标地址变化在程序拥有多个模块的时候更为严重。人工绑定进行指令的修正以确保所有的跳转目标地址都正确,在程序规模越来越大以后变得越来越复杂和繁琐。
没办法,这种黑暗的程序员生活是没有办法容忍的。先驱者发明了汇编语言,这相比机器语言来说是个很大的进步。汇编语言使用接近人类的各种符号和标记来帮助记忆,比如指令采用两个或三个字母的缩写,记住“jmp”比记住0001XXXX是**跳转(jump)**指令容易得多了;汇编语言还可以使用符号来标记位置,比如一个符号“divide”表示一个除法子程序的起始地址,比记住从某个位置开始的第几条指令是除法子程序方便得多。最重要的是,这种符号的方法使得人们从具体的指令地址中逐步解放出来。比如前面纸带程序中,我们把刚开始第5条指令开始的子程序命名为“foo”,那么第一条指令的汇编就是:
jmp foo
当然人们可以使用这种符号命名子程序或跳转目标以后,不管这个“foo”之前插入或减少了多少条指令导致“foo”目标地址发生了什么变化,汇编器在每次汇编程序的时候会重新计算“foo”这个符号的地址,然后把所有引用到“foo”的指令修正到这个正确的地址。整个过程不需要人工参与,对于一个有成百上千个类似的符号的程序,程序员终于摆脱了这种低级的繁琐的调整地址的工作,用一句政治口号来说叫做“极大地解放了生产力”。符号(Symbol) 这个概念随着汇编语言的普及迅速被使用,它用来表示一个地址,这个地址可能是一段子程序(后来发展成函数)的起始地址,也可以是一个变量的起始地址。
有了汇编语言以后,生产力大大提高了,随之而来的是软件的规模也开始日渐庞大。这时程序的代码量也已经开始快速地膨胀,导致人们要开始考虑将不同功能的代码以一定的方式组织起来,使得更加容易阅读和理解,以便于日后修改和重复使用。自然而然,人们开始将代码按照功能或性质划分,分别形成不同的功能模块,不同的模块之间按照层次结构或其他结构来组织。这个在现代的软件源代码组织中很常见,比如在C语言中,最小的单位是变量和函数,若干个变量和函数组成一个模块,存放在一个“.c”的源代码文件里,然后这些源代码文件按照目录结构来组织。在比较高级的语言中,如Java中,每个类是一个基本的模块,若干个类模块组成一个包(Package),若干个包组合成一个程序。
在现代软件开发过程中,软件的规模往往都很大,动辄数百万行代码,如果都放在一个模块肯定无法想象。所以现代的大型软件往往拥有成千上万个模块,这些模块之间相互依赖又相对独立。这种按照层次化及模块化存储和组织源代码有很多好处,比如代码更容易阅读、理解、重用,每个模块可以单独开发、编译、测试,改变部分代码不需要编译整个程序等。
在一个程序被分割成多个模块以后,这些模块之间最后如何组合形成一个单一的程序是须解决的问题。模块之间如何组合的问题可以归结为模块之间如何通信的问题,最常见的属于静态语言的C/C++模块之间通信有两种方式,一种是模块间的函数调用,另外一种是模块间的变量访问。函数访问须知道目标函数的地址,变量访问也须知道目标变量的地址,所以这两种方式都可以归结为一种方式,那就是模块间符号的引用。模块间依靠符号来通信类似于拼图版,定义符号的模块多出一块区域,引用该符号的模块刚好少了那一块区域,两者一拼接刚好完美组合如下图。这个模块的拼接过程就是链接(Linking)。
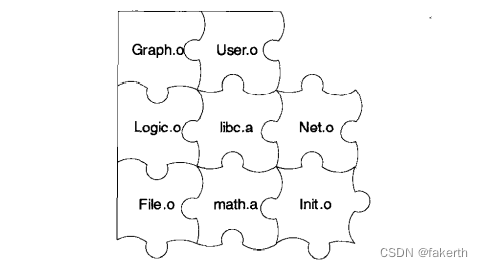
这种基于符号的模块化的一个直接结果是链接过程在整个程序开发中变得十分重要和突出。链接器将这些编译后的模块链接到一起,最终产生一个可以执行的程序。
静态链接
程序设计的模块化是人们一直在追求的目标,因为当一个系统十分复杂的时候,我们不得不将一个复杂的系统逐步分割成小的系统以达到各个突破的目的。一个复杂的软件也如此,人们把每个源代码模块独立地编译,然后按照须要将它们“组装”起来,这个组装模块的过程就是链接(Linking)。链接的主要内容就是把各个模块之间相互引用的部分都处理好,使得各个模块之间能够正确地衔接。链接器所要做的工作其实跟前面所描述的“程序员人工调整地址”本质上没什么两样,只不过现代的高级语言的诸多特性和功能,使得编译器、链接器更为复杂,功能更为强大,但从原理上来讲,它的工作无非就是把一些指令对其他符号地址的引用加以修正。链接过程主要包括了地址和空间分配(Address and StorageAllocation)、符号决议(Symbol Resolution)和重定位(Relocation)等这些步骤。
符号决议有时候也被叫做符号绑定( Symbol Binding )、名称绑定(Name Binding )、名称决议(Name Resolution ),甚至还有叫做地址绑定(Address Binding )、指令绑定( lnstruction Binding ) 的,大体上它们的意思都一样,但从细节角度来区分,它们之间还是存在一定区别的,比如“决议”更倾向于静态链接,而“绑定”更倾向于动态链接,即它们所使用的范围不一样。在静态链接,我们将统一称为符号决议。
最基本的静态链接过程如图所示。每个模块的源代码文件(如,c)文件经过编译器编译成目标文件(Object File,一般扩展名为.o或.obj),目标文件和库(Library) 一起链接形成最终可执行文件。而最常见的库就是运行时库(Runtime Library),它是支持程序运行的基本函数的集合。库其实是一组目标文件的包,就是一些最常用的代码编译成目标文件后打包存放。
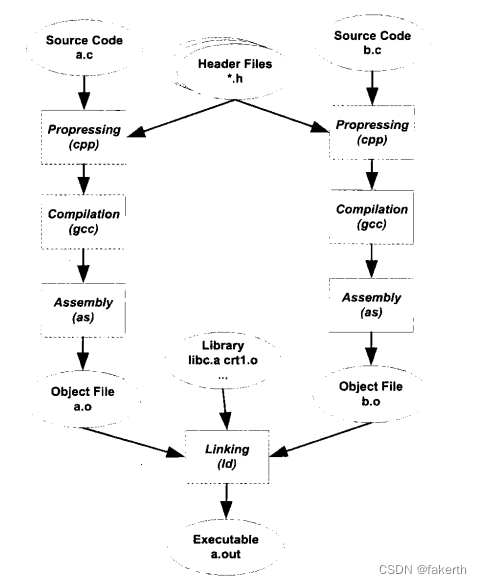
我们认为对于Object文件没有一个很合适的中文名称,把它叫做中间目标文件比较合适,简称为目标文件,后面的内容都将称Object文件为目标文件,很多时候我们也把目标文件称为模块。
现代的编译和链接过程也并非想象中的那么复杂,它还是一个比较容易理解的概念。比如 我们在程序模块main.c中使用另外一个模块func.c中的函数foo()。我们在main.c模块中每一处调用foo的时候都必须确切知道foo这个函数的地址,但是由于每个模块都是单独编译的,在编译器编译main.c的时候它并不知道foo函数的地址,所以它暂时把这些调用foo的指令的目标地址搁置,等待最后链接的时候由链接器去将这些指令的目标地址修正。如果没有链接器,须要我们手工把每个调用foo的指令进行修正,则填入正确的foo函数地址。当func.c模块被重新编译,foo函数的地址有可能改变时,那么我们在main.c中所有使用到foo的地址的指令将要全部重新调整。这些繁琐的工作将成为程序员的噩梦。使用链接器,你可以直接引用其他模块的函数和全局变量而无须知道它们的地址,因为链接器在链接的时候,会根据你所引用的符号foo,自动去相应的func.c模块查找foo的地址,然后将main.c模块中所有引用到 foo的指令重新修正,让它们的目标地址为真正的foo函数的地址。这就是静态链接的最基本的过程和作用。
在链接过程中,对其他定义在目标文件中的函数调用的指令须要被重新调整,对使用其他定义在其他目标文件的变量来说,也存在同样的问题。让我们结合具体的CPU指令来了解这个过程。假设我们有个全局变量叫做var,它在目标文件A里面。我们在目标文件B里面要访问这个全局变量,比如我们在目标文件B里面有这么一条指令:
movl $0x2a,var
这条指令就是给这个var变量赋值0x2a,相当于C语言里面的语句var=42。然后我们编译目标文件B,得到这条指令机器码,如下图所示:
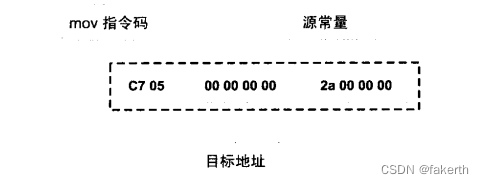
由于在编译目标文件B的时候,编译器并不知道变量var的目标地址,所以编译器在没法确定地址的情况下,将这条mov指令的目标地址置为0,等待链接器在将目标文件A和B链接起来的时候再将其修正。我们假设A和B链接后,变量var的地址确定下来为0x1000,那么链接器将会把这个指令的目标地址部分修改成0x1000。这个地址修正的过程也被叫做重定位(Relocation),每个要被修正的地方叫一个重定位入口(Relocation Entry)。重定位所做的就是给程序中每个这样的绝对地址引用的位置“打补丁”,使它们指向正确的地址。